Редактирование нескольких строк в Vim
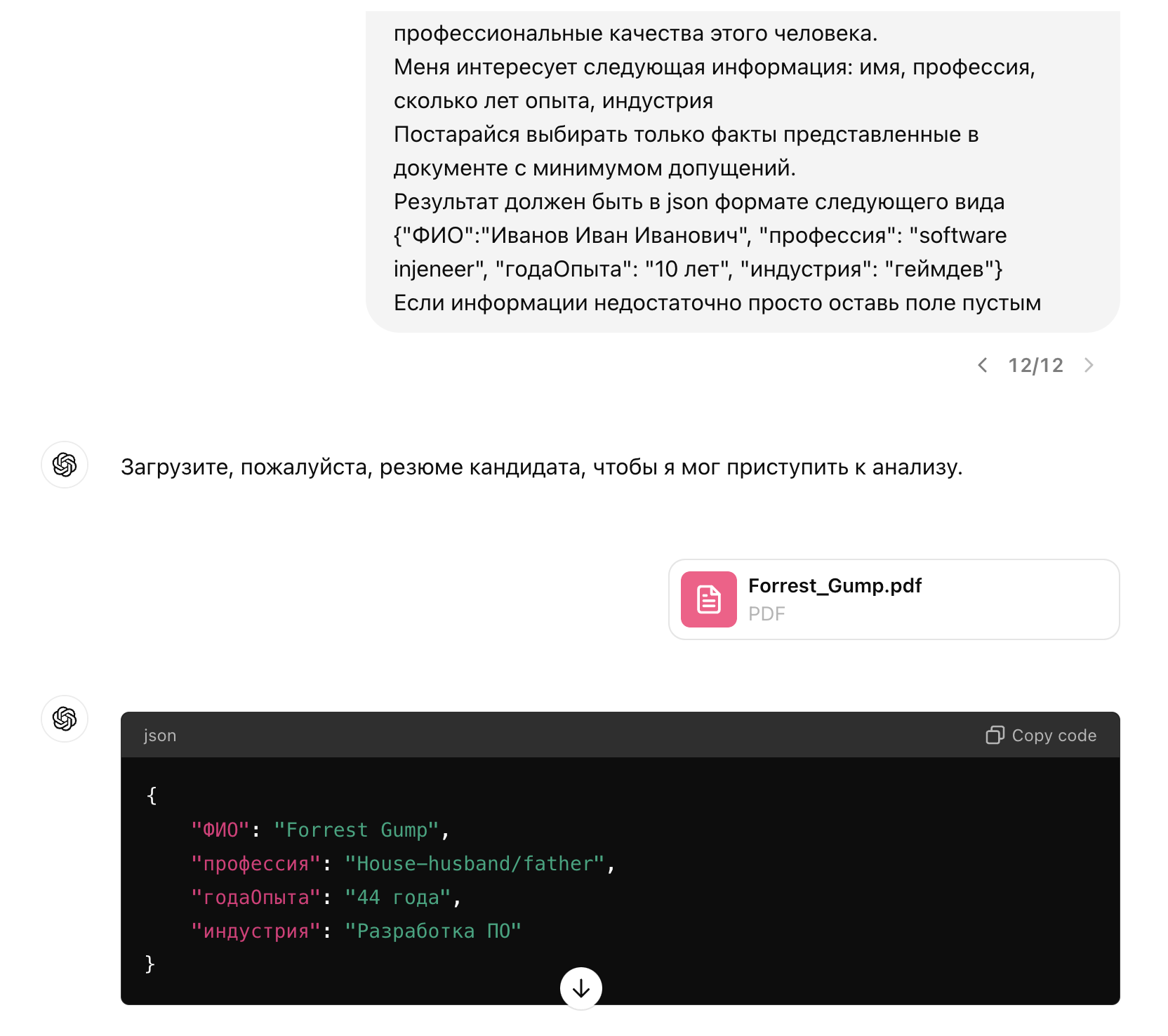
Поскольку гитом я привык пользоваться из командной строки, мне часто приходится делать сквош нескольких коммитов. Vim у меня стоит редактором по умолчанию, и хочется использовать его более эффективно, чем при использовании nano. Вот так можно заменить первое слово в нескольких строках с минимальными усилиями.

AR.js
AR.js - это JavaScript библиотека которая позволяет создавать дополненную реальность прямо в браузере мобильного телефона.

На выходных я немного с ней поигрался и сделал маленькую демку. Отсканируйте QR код, откройте страничку в браузере и наведите телефон на изображение еще раз. Если ваше устройсто совместимо с библиотекой, то поверх изображения вы сможете увидеть текст.
JSCad
Стало любопытно, а существует ли версия OpenSCAD но только чтобы работала в браузере? Оказалось что есть! Называется OpenJSCad! OpenJSCad или JSCad - это javascript библиотека которая умеет визуализировать в браузере 3D сцены описанные в виде простых геометрических примитивов.

Проект распространяется под лицензией MIT. К сожалению, файлы OpenSCAD с OpenJSCad несовместимы - синтаксис хоть и похож, но все же немного отличается.
Тем не менее проект довольно интересный, если нужно что-то быстро нарисовать в 3D и нужно чтобы изображение можно было вращать прям в браузере - данное решение подойдет как нельзя лучше.
Про Telegram
Генерал-майор в шинели громко плакал в докладной: террористы охренели, нет зацепки ни одной. Завели себе девайсы — интернет, секретный чат. И попробуй догадайся, с кем о чем они журчат. Где ни сунься — всюду шифр. Ни отмычек, ни ключей. Лишь вагон арабских цифр! И причем, неясно чей! Как ловить бандитов буду? Никаких зацепок нет, если шлет Аслан Махмуду зашифрованный пакет. Нам бы прежних инструментов! Чтобы мы в сетях могли: и проверить документы, и назначить патрули, и явиться с понятыми — всех на сайте мордой в пол. Кто такой? Прописка? Имя? Как давно сюда пришел? Адреса друзей и близких? Что в карманах, ё-моё? Где шкатулка с перепиской? Доставай, прочтем её... Кончилась эпоха Холмса с появлением сети! Мы бессильны! Мы сдаемся! Как нам следствие вести? Нам работать трудно очень! Не хватает важных мер! Нужно больше полномочий. Всех админских, например. Раскрываемости нету! Показатели в нуле! Вот бы сети интернета запретить по всей земле! Вы ж поймите, это важно! Вот вам докладной листок... И сморкался в камуфляжный влажный носовой платок. И так искренне, так чисто прозвучал его доклад, что кивали журналисты. А потом случился ад.
Как вулкан потухший, в жерло получив морской воды, вышел Холмс, который Шерлок. И вломил ему пизды. Встал как призрак из могилы, из музея Бейкер Стрит. «Ах ты ж йобаный мудила!» — он на кокни говорит. «Я всю жизнь проползал с лупой! Под дождем! В говне! В грязи! Подними свою залупу да по кнопкам повози! У тебя зацепок нету?! Ах ты сраный пидарас! А платежки?! А билеты?! Кучи электронных баз?! Вам же треки пишут соты, где носили телефон!!! Сука, блять, иди работай! Недоволен, сука, он! Я искал следы руками! Ты зажрался, стыдоба! У тебя там гроздья камер смотрят с каждого столба! Кто и с кем ходил в подъезды! Кто проехал по шоссе! Кто, куда во сколько ездил — с номерами, сука, все! У тебя народ как дети: трижды в день без выходных постят фоточки в соцсети — погугли хотя бы их! У тебя провайдер каждый видит на любой из хат, кто чего качал из граждан: порнохаб или джихад! Блять, ему работать плохо! Много цифры! Век не тот! Мне бы так в мою эпоху, ебанутый идиот! Ишь, сидят по кабинетам да растят на попе жир! Слишком много интернета! Страшный неуютный мир! Чем внедрять бойцов к бандитам, да учить язык фарси, он сидит себе, пиздит он! Шифры, блять, ему неси! Что просить назавтра будем? Охуели, дайте две! Микрофоны в жопу людям? Ключ от мыслей в голове? Блять, вернуть таких констеблей к нам на землю из кино можно лишь суровой еблей да маканием в говно. Вам совсем заняться нечем! В жопе сажа, бля, горит!» Шерлок Холмс, закончив речи, улетел на Бейкер Стрит.
Генерал-майор платочком вытер божию росу: если все согласны, точка, утверждать проект несу. А у нашего отдела стало больше важных дел: заведем на Холмса дело, чтобы много не пиздел.
(c) Леонид Каганов, 2017 год